Shuffle 简单介绍
Shuffle是MapReduce框架中的一个特定的阶段,介于Map阶段和Reduce 阶段之间。当Map的输出结果在被Reduce使用之前,输出结果先按key哈希,然后分发到每一个Reducer上,这个过程就是shuffle。由于shuffle涉及到了磁盘I/O和网络I/O,以及序列化,因此shuffle性能的高低直接影响到了整个程序的运行效率。
下面两幅图中Map阶段和Reduce 阶段之间的复杂处理就是shuffle,也形象地说明了为什么shuffle的性能会影响整个阶段。
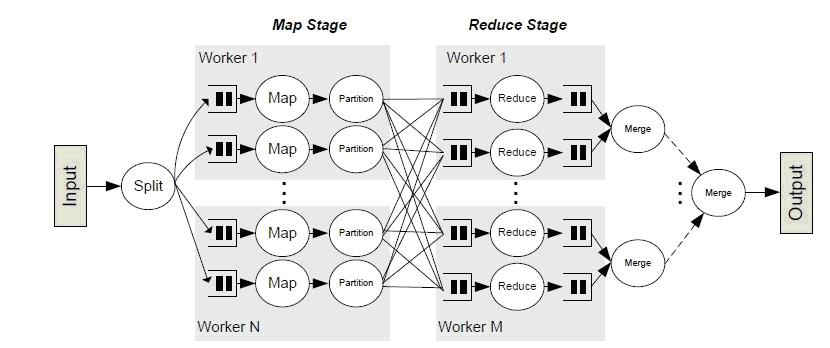
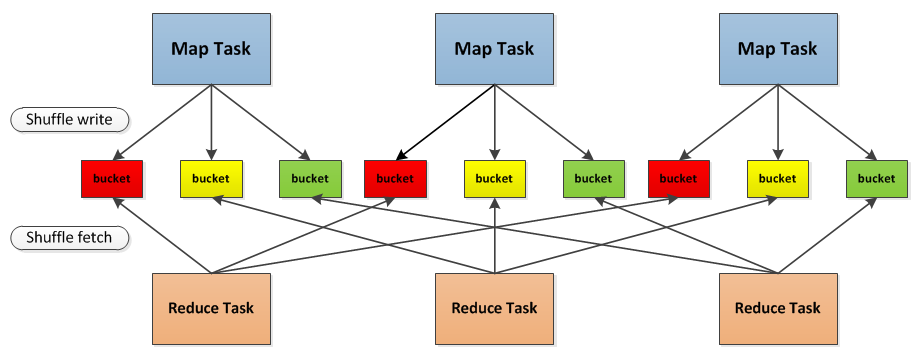
很多时候一些性能问题都是shuffle这里出现的,比如因为任务执行的数据集过大而导致shuffle为每一个任务所创建哈希表变非常大,以至于无法加载到内存中,出现OutOfMemory 的错误。
两个很详细说明shuffle在spark和haddopp的区别的文章,要详细了解shuffle请仔细阅读:
http://jerryshao.me/architecture/2014/01/04/spark-shuffle-detail-investigation/
https://github.com/JerryLead/SparkInternals/blob/master/markdown/4-shuffleDetails.md