Spark Streaming 介绍
Spark Streaming 是为了支持实时数据流计算而在spark api 扩展实现的流式计算框架.
由于spark rdd 的特点,所以spark streaming 和其他流式计算框架概念上有些区别.
spark streaming 官方列举的数据源获取方式有kafka、flume、Twitter、 ZeroMQ、Kinesis等.当然,由于是spark,rdd获取数据的方式完全可以自行实现,所以数据获取方式是无限的.
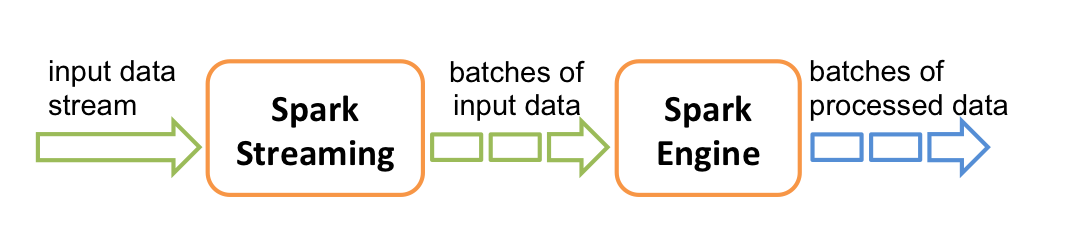
简单工作原理如图所示.spark streaming 将数据流切成批数据交由spark 引擎处理.
在sbt的项目中要引入spark streaming 的包很简单,只需一句:
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "1.3.1"
spark streaming 和 spark一样都是从 context开始,只不过叫 StreamingContext,其可以通过sparkconf或者sparkcontext创建.
val ssc = new StreamingContext(conf, Seconds(1))
或
val ssc = new StreamingContext(sc, Seconds(1))
第二个参数,如例子中的Seconds(1) 是指以多长的时间段来切割数据流.
一个sparkcontext同时只能有一个spark streaming 计算关联
在JVM中,同一时间只能有一个StreamingContext处于活跃状态